
Нередко бывает нужно узнать пароль, имея на руках только хеш. Для перебора вариантов можно использовать свой компьютер, но гораздо быстрее воспользоваться уже существующей базой данных. Даже в общедоступных базах содержатся десятки миллионов пар хеш — пароль, и поиск по ним через облачный сервис занимает считаные секунды.
Еще по теме: Определение хеша
В мире существует несколько зеттабайт цифровых данных, но далеко не вся эта информация уникальна: повторы разбросаны по миллиардам носителей и серверов. Независимо от типа данных, для работы с ними требуется решать одни и те же принципиальные задачи. Это снижение избыточности за счет частичного устранения повторов (дедупликация), проверка целостности, инкрементное создание резервных копий и авторизация пользователей. Конечно, последний аспект интересует нас больше всего, однако все эти технические приемы базируются на общих методах обработки данных с использованием хеширования. Существуют облачные сервисы, которые позволяют использовать эту процедуру быстрее — с хорошо известными целями.
На первый взгляд кажется странным, что в разных задачах применяется общая процедура вычисления и сравнения контрольных сумм или хешей — битовых последовательностей фиксированной длины. Однако этот метод действительно универсален. Контрольные суммы служат своеобразными цифровыми отпечатками файлов, ключей, паролей и других данных, называемых в криптографии messages — сообщения. Хеши (или дайджесты, от англ. digest) позволяют сравнивать их между собой, быстро обнаруживать любые изменения и обезопасить проверку доступа. Например, с помощью хешей можно проверять соответствие введенных паролей, не передавая их в открытом виде.
Математически этот процесс выполняется одним из алгоритмов хеширования — итерационного преобразования блоков данных, на которые разбивается исходное сообщение. На входе может быть что угодно — от короткого пароля до огромной базы данных. Все блоки циклично дописываются нулями или урезаются до заданной длины до тех пор, пока не будет получен дайджест фиксированного размера.
Обычно хеши записываются в шестнадцатеричном виде. Так их гораздо удобнее сравнивать на вид, а запись получается в четыре раза короче двоичной. Самые короткие хеши получаются при использовании Adler-32, CRC32 и других алгоритмов с длиной дайджеста 32 бита. Самые длинные — у SHA-512. Кроме них, существует с десяток других популярных хеш-функций, и большинство из них способно рассчитывать дайджесты промежуточной длины: 160, 224, 256 и 384 бита. Попытки создать функцию с увеличенной длиной хеша продолжаются, поскольку чем длиннее дайджест, тем больше разных вариантов может сгенерировать хеш-функция.
Неповторимость — залог надежности
Уникальность хеша — одно из его ключевых свойств, определяющее криптостойкость системы шифрования. Дело в том, что число вариантов возможных паролей теоретически бесконечно, а вот число хешей всегда конечное, хоть и очень большое. Дайджесты любой хеш-функции будут уникальны лишь до определенной степени. Степени двойки, если быть точным. К примеру, алгоритм CRC32 дает множество всего из 232 вариантов, и в нем трудно избежать повторений. Большинство других функций использует дайджесты длиной 128 или 160 бит, что резко увеличивает число уникальных хешей — до 2’28 и 2160 соответственно.
Совпадение хешей от разных исходных данных (в том числе паролей) называют коллизией. Она может быть случайной (встречается на больших объемах данных) или псевдослучайной — используемой в целях атаки. На эффекте коллизии основан взлом разных криптографических систем — в частности, протоколов авторизации. Все они сначала считают хеш от введенного пароля или ключа, а затем передают этот дайджест для сравнения, часто примешивая к нему на каком-то этапе порцию псевдослучайных данных, или используют дополнительные алгоритмы шифрования для усиления защиты. Сами пароли нигде не сохраняются: передаются и сравниваются только их дайджесты. Здесь важно то, что после хеширования абсолютно любых паролей одной и той же функцией на выходе всегда получится дайджест одинакового и заранее известного размера.
Псевдореверс
Провести обратное преобразование и получить пароль непосредственно из хеша невозможно в принципе, даже если очистить его от соли, поскольку хеширование — это однонаправленная функция. Глядя на полученный дайджест, нельзя понять ни объем исходных данных, ни их тип. Однако можно решить сходную задачу: сгенерировать пароль с таким же хешем. Из-за эффекта коллизии задача упрощается: возможно, ты никогда не узнаешь настоящий пароль, но найдешь совершенно другой, дающий после хеширования по этому же алгоритму требуемый дайджест.
Методы оптимизации расчетов появляются буквально каждый год. Ими занимаются команды HashClash, Distributed Rainbow Table Generator и других международных проектов криптографических вычислений. В результате на каждое короткое сочетание печатных символов или вариант из списка типичных паролей хеши уже вычислены. Их можно быстро сравнить с перехваченным, пока не найдется полное совпадение.
Раньше на это требовались недели или месяцы процессорного времени, которые в последние годы удалось сократить до нескольких часов благодаря многоядерным процессорам и перебору в программах с поддержкой CUDA и OpenCL. Админы нагружают расчетами таблиц серверы во время простоя, а кто-то арендует виртуальный кластер в Amazon ЕС2.
Поиск хеша гуглом
Далеко не все сервисы готовы предоставить услугу поиска паролей по хешам бесплатно. Где-то требуется регистрация и крутится тонна рекламы, а на многих сайтах можно встретить и объявления об услуге платного взлома. Часть из них действительно использует мощные кластеры и загружает их, ставя присланные хеши в очередь заданий, но есть и обычные пройдохи. Они выполняют бесплатный поиск за деньги, пользуясь неосведомленностью потенциальных клиентов.
Вместо того чтобы рекламировать здесь честные сервисы, я предложу использовать другой подход — находить пары хеш — пароль в популярных поисковых системах. Их роботы-пауки ежедневно прочесывают веб и собирают новые данные, среди которых есть и свежие записи из радужных таблиц.
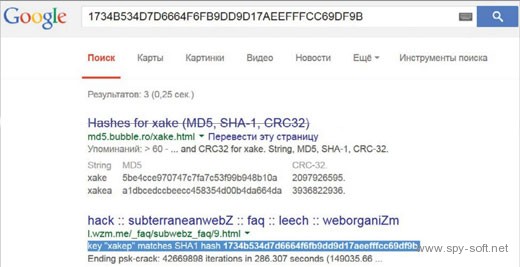
Поэтому для начала просто напиши хеш в поисковой строке Google. Если ему соответствует какой-то словарный пароль, то он (как правило) отобразится среди результатов поисковой выдачи уже на первой странице. Единичные хеши можно погуглить вручную, а большие списки будет удобнее обработать с помощью скрипта BozoCrack
Искать XOR вычислять
Популярные алгоритмы хеширования работают настолько быстро, что к настоящему моменту удалось составить пары хеш — пароль почти для всех возможных вариантов функций с коротким дайджестом. Параллельно у функций с длиной хеша от 128 бит находят недостатки в самом алгоритме или его конкретных реализациях, что сильно упрощает взлом.
В девяностых годах крайне популярным стал алгоритм MD5, написанный Рональдом Ривестом. Он стал широко применяться при авторизации пользователей на сайтах и при подключении к серверам клиентских приложений. Однако его дальнейшее изучение показало, что алгоритм недостаточно надежен. В частности, он уязвим к атакам по типу псевдослучайной коллизии. Иными словами, возможно преднамеренное создание другой последовательности данных, хеш которой будет в точности соответствовать известному.

Поскольку дайджесты сообщений широко применяются в криптографии, на практике использование алгоритма MD5 сегодня приводит к серьезным проблемам. Например, с помощью такой атаки можно подделать цифровой сертификат х.509. В том числе возможна подделка сертификата SSL, позволяющая злоумышленнику выдавать свой фейк за доверенный корневой сертификат (СА). Более того, в большинстве наборов доверенных сертификатов легко найти те, которые по-прежнему используют алгоритм MD5 для подписи. Поэтому существует уязвимость всей инфраструктуры открытых ключей (PKI) для таких атак.
Изнурительную атаку перебором устраивать придется только в случае действительно сложных паролей (состоящих из большого набора случайных символов) и для хеш-функций с дайджестами большой длины (от 160 бит), у которых пока не нашли серьезных недостатков. Огромная масса коротких и словарных паролей сегодня вскрывается за пару секунд с помощью онлайн-сервисов.
Расшифровка хеша онлайн
1. Проект «Убийца хешей» существует уже почти восемь лет. Он помогает вскрыть дайджесты MD5, SHA-160 и NTLM. Текущее количество известных пар составляет 43,7 миллиона. На сайт можно загружать сразу несколько хешей для параллельного анализа. Пароли, содержащие кириллицу и символы других алфавитов, кроме английского, иногда находятся, но отображаются в неверной кодировке. Еще здесь проводится постоянный конкурс взлома паролей по их хешам и доступны утилиты для облегчения этой задачи — например, программы для объединения списков паролей, их переформатирования и устранения повторов.
Hash Killer не дружит с кириллицей, но знает кириллические пароли.
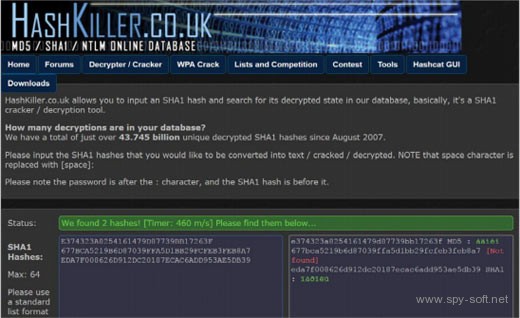
«Убийца хешей» нашел три пароля из пяти за пол секунды.
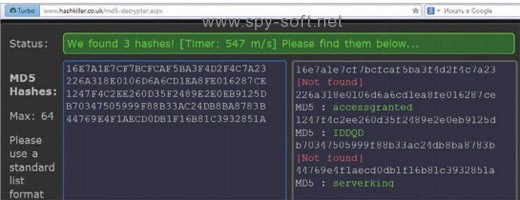
2. Крэк-станция поддерживает работу с хешами практически всех реально используемых типов. LM, NTLM, MySQL 4.1+, MD2/4/5 + MD5-half, SHA-160/224/256/384/512, ripeMD160 и Whirlpool. За один раз можно загрузить для анализа до десяти хешей. Поиск проводится по индексированной базе. Для MD5 ее объем составляет 15 миллионов пар (около 190 Гб) и еще примерно по 1,5 миллиона для каждой другой хеш-функции.
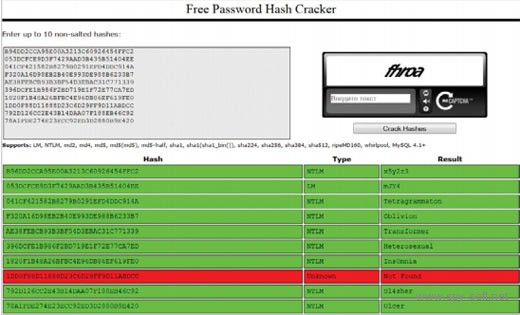
По уверениям создателей в базу включены из Англоязычной версии Википедии и большинство популярных паролей, собранных из общедоступных списков. Среди них есть и хитрые варианты со сменой регистра, литспиком, повтором символов, зеркалированием и прочими трюками. Однако случайные пароли даже из пяти символов становятся проблемой — в моем тесте половина из них не была найдена даже по LM-хешам.
3. CloudCracker бесплатный сервис мгновенного поиска паролей по хешам MD5 и SHA-1. Тип дайджеста определяется автоматически по его длине.
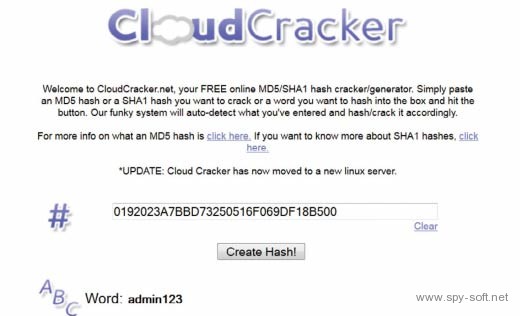
Пока CloudCracker находит соответствия только хешам некоторых английских слов и распространенных паролей, вроде admin123. Даже короткие пароли из случайных наборов символов типа D358 он не восстанавливает по дайджесту MD5.
4. Сервис MD5Decode содержит базу паролей, для которых известны значения MD5. Он также показывает все остальные хеши, соответствующие найденному паролю: MD2, MD4, SHA (160-512), RIPEMD (128-320), Whirlpool-128, Tiger (128-192 в 3-4 прохода), Snefru-256, GOST, Adler-32, CRC32, CRC32b, FNV (132/164), JOAAT 8, HAVAL (128-256 в 3-5 проходов).
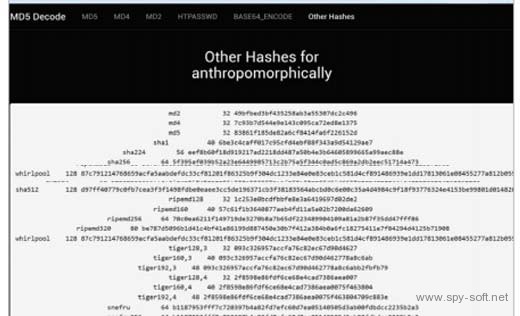
Если число проходов не указано, то функция вычисляет хеш в один проход. Собственного поиска на сайте пока нет, но пароль или его хеш можно написать прямо в адресной строке браузера, добавив его после адреса сайта и префикса /encrypt/.
5. Проект с говорящим названием MD5Decrypt тоже позволяет найти соответствие только между паролем и его хешем MD5. Зато у него есть собственная база из 10 миллионов пар и автоматический поиск по 23 базам дружественных сайтов. Также на сайте имеется хеш-калькулятор для расчета дайджестов от введенного сообщения по алгоритмам MD4, MD5 и SHA-1.
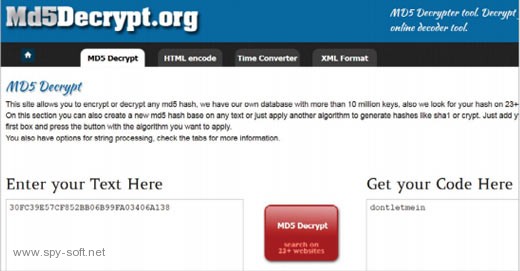
MD5Decrypt находит составные словарные пароли, но хеши на анализ при ни мает только по одному
6. Еще один сайт, MD5Lab получил хостинг у CloudFare в Сан-Франциско. Искать по нему пока неудобно, хотя база растет довольно быстро. Просто возьми на заметку.
Универсальный подход
Среди десятка хеш-функций наиболее популярны MD5 и SHA-1, но точно такой же подход применим и к другим алгоритмам. К примеру, файл реестра SAM в ОС семейства Windows по умолчанию хранит два дайджеста каждого пароля: LM-хеш (устаревший тип на основе алгоритма DES) и NT-хеш (создается путем преобразования юникодной записи пароля по алгоритму MD4). Длина обоих хешей одинакова (128 бит), но стойкость LM значительно ниже из-за множества упрощений алгоритма.
Постепенно оба типа хешей вытесняются более надежными вариантами авторизации, но многие эту старую схему используют в исходном виде до сих пор. Скопировав файл SAM и расшифровав его системным ключом из файла SYSTEM, атакующий получает список локальных учетных записей и сохраненных для них контрольных значений — хешей.
Далее взломщик может найти последовательность символов, которая соответствует хешу администратора. Так он получит полный доступ к ОС и оставит в ней меньше следов, чем при грубом взломе с помощью банального сброса пароля. Напоминаю, что из-за эффекта коллизии подходящий пароль не обязательно будет таким же, как у реального владельца компьютера, но для Windows разницы между ними не будет вовсе. Как пела группа Bad Religion, «Cause to you I’m just a number and a clever screen name».
Аналогичная проблема существует и в других системах авторизации. Например, в протоколах WPA/WPA2, широко используемых при создании защищенного подключения по Wi-Fi. При соединении между беспроводным устройством и точкой доступа происходит стандартный обмен начальными данными, включающими в себя handshake. Во время «рукопожатия» пароль в открытом виде не передается, но в эфир отправляется ключ, основанный на хеш-функ-ции. Нужные пакеты можно перехватить, переключив с помощью модифицированного драйвера адаптер Wi-Fi в режим мониторинга. Более того, в ряде случаев можно не ждать момента следующего подключения, а инициализировать эту процедуру принудительно, отправив широковещательный запрос deauth всем подключенным клиентам. Уже в следующую секунду они попытаются восстановить связь и начнут серию «рукопожатий».
Сохранив файл или файлы с хендшейком, можно выделить из них хеш пароля и либо узнать сам пароль, либо найти какой-то другой, который точка доступа примет точно так же. Многие онлайн-сервисы предлагают провести анализ не только чистого хеша, но и файла с записанным хендшейком. Обычно требуется указать файл рсар и SSID выбранной точки доступа, так как ее идентификатор используется при формировании ключа PSK.
Проверенный ресурс CloudCracker о котором в последние годы писали все кому не лень, по-прежнему хочет за это денег. Gpuhash принимает биткоины. Впрочем, есть и бесплатные сайты с подобной функцией. Например, DarklRCop.
Пока с помощью онлайн-сервисов и радужных таблиц находятся далеко не все пары хеш — пароль. Однако функции с коротким дайджестом уже побеждены, а короткие и словарные пароли легко обнаружить даже по хешам SHA-160. Особенно впечатляет мгновенный поиск паролей по их дайджестам с помощью Гугла. Это самый простой, быстрый и совершенно бесплатный вариант.
Еще по теме: Cloudtopolis: Мощный инструмент для взлома хешей
")


Если до этого было проделан ключ к примеру cast128
base64 и придиьи хешем.. то нафиг не кто не че не сможет… должно там быть что то .только так.
Большое спасибо,я пытался узнать пароль от компа,который забыл и скачал приложение Reset Windows Password,но оно слишком долго искало и не могло найти,а показало только NT хэш,но с помощью сайта Hash Killer я расшифровал его!!!
И не стыдно подписываться школоло дилетанту таким громким именем? Или как всегда, чем ярче обертка, тем скуднее содержимое?
Здравствуйте господа, подскажите пожалуйста, если прога шифрует определенное число в хэш, то в следующий раз, если она это число зашифрует, то хэши буду совпадать или же будут разные?
Rainbowcrack поможет расшифровать хэш!
Лучше Хэшкет нет ничего!
Пожалуйста, расшифруйте хеш 06e6a2d2f0db992363b53a56d9ccb4e2 и af6d34f203e3fe55987ea9c1954b277b. Все они на структуре NTLM. Надо очень, сижу уже 4 часа не могу расшифровать! Даже один.